

UTF8 đã dạy tiếng việt cho máy tính như thế nào? Hành trình mang tiếng việt đi khắp thế giới
Posted on October 3, 2022 • 9 minutes • 1715 words
Mở đầu:
Lời đầu : Có lẽ nếu là một người dân hà nội bạn đã quá quen với những câu hỏi xã giao thường ngày như:
mày biết bố mày là ai không? mày có biết tiếng việt không ?Nhiều đến mức lắm lúc mình phải dừng xe lại và tự hỏi bố thằng này là ai nhỉ? chắc phải là một danh tướng nào đó để khi ghép với khí thế đó. Hai từ “Bố tướng” mới mô tả một cách chính xác đến thế.
Thường thì mình không biết bố của những người đó là ai . Nên sẽ hỏi lại chiếc điện thoại thông minh của mình:
Mình: "hey seri , mày có biết bố thằng này là ai không?"
Seri: "Không"
Mình: "Thế còn tiếng việt thì sao? mày biết tiếng việt chứ"
Seri: "Có"
Mình: "Mày gửi giúp tao một tin nhắn cho công an phường bằng tiếng việt
để hỏi giúp tao bố thằng này là ai nhé?"
Seri: "OK"10p sau mọi chuyện trở nên êm đẹp.
Đấy các bạn thấy đấy quá khó để trả lời cho câu hỏi " bố mày là ai? " Khó hơn cả việc dạy chiếc điện thoại biết tiếng việt.
Thế nên là hôm nay mình sẽ chỉ trình bày cái cách để một chiếc điện thoại biết được tiếng việt như nào? thay vì trả lời cho câu hỏi bố bạn là ai? =))
Chào mừng người anh em đến với bài viết UTF8 đã dạy tiếng việt cho máy tính như thế nào? =))
Bạn nên tham khảo trước bài : https://hoangtrungkien210895.github.io/en/blog/van-vat-internet/ để biết được mọi thứ trên đời đều có thể được định nghĩa trên các ký tự 0 và 1 .
Các lý thuyết cơ bản:
Các bạn biết đấy con người bình thường sẽ dùng hệ số đếm 10 (bao gồm 10 ký tự từ 0 đến 9 ) còn hệ số đếm ưa thích của máy lại là 2 (gồm 2 ký tự 1 và 0 )
Mỗi cách kết hợp ký tự của hệ đếm sẽ ra một con số với một giá trị đại diện. mình sẽ mô tả một chút cách đếm của hệ 10 và hệ 2 để các bạn thấy nó tương đồng nhau :
-
Hệ số 10 : ta có “789” sẽ là kết hợp của các ký tự “7” “8” “9” được đặt từ (trái qua phải ) . bạn thường nhìn và đọc nó là “7 trăm 8 mươi 9” phải không nào ? Cách bạn tính giá trị của một chữ số là từ ( trái -> phải ) đúng không? . Một trong những điều nhầm lẫn của mọi người =))) . Giá trị của “789” phải được tính từ ( phải -> trái ) với hệ cơ số 10 : “789” = 9x10^0 + 8x10^1 + 7x10^2 tương đương 9 + 80 + 700 ( =)) đây mới là cách giải thích cho việc bạn đọc “7 trăm 8 mươi 9” ) và đây cũng nguyên do chúng ta gọi hệ số chúng ta sử dụng là hệ 10 =)) k phải chỉ là chúng gồm 10 ký tự số đâu nhé
-
Hệ số 2: cách tính giá trị cũng giống với hệ 10. vd ta có “101” thì giá trị ta chỉ cần tính từ phải -> trái hệt như cái cách mà hệ 10 làm chỉ thay hệ số nhân từ 10 thành 2 là ok : “101” = 1x2^0 + 0x2^1 + 1x2^2 tương đương 1 + 0 + 4 = 5
=> vậy từ việc ghép những bit 1 và 0 thành các dãy (11001 hoặc 00110011 ) thì ta sẽ nhận những giá trị tương ứng với các dãy đó.
Nếu bạn đọc 1 file tài liệu dạng văn bản thuần thì máy tính sẽ đọc từ trái qua phải theo đơn vị mỗi 8 bit (1 byte) sẽ hình nên một giá trị mỗi giá trị sẽ tương ứng với một ký tự (theo chuẩn ascii ‘American Standard Code for Information Interchange’ ) và hiển thị nó . Như vậy với các cách đọc này thì giá trị nhỏ nhất theo bit là 0000 0000 và lớn nhất là 1111 1111 tương đương từ 0 -> 255 . Vậy với cách đọc này thì văn bản của chúng ta chỉ có thể được máy tính đọc và hiện được với 256 ký tự và trong những ký tự này tất nhiên rồi không có tiếng việt.
=> chúng ta cần một chuẩn đọc văn bản khác để có thể hiển thị nhiều hơn các ký tự đặc biệt : UTF-8

UTF-8 cũng hình thành từ ý tưởng với mỗi ký tự bất kì thì sẽ được đánh cho nó 1 giá trị duy nhất thể hiện cho ký tự đó Trong UTF-8 nếu viết một từ “á” thì giá trị biểu diễn của nó sẽ là : 225 (chuyển giá trị sang hệ 16 code point: 00E1 ) hay nói ngược lại nếu ta có giá trị 225 ta sẽ biết được nó tương đương với từ “á”. ta gọi giá trị này (255) là code point.
Và để mang tiếng việt đến cho hệ xử lý biết đến thì ta phải nói cho nó ê đừng có đọc tuần tự theo kiểu 8 bit(1 byte) liên tiếp trở thành một ký tự nữa . Hãy “khôn” lên đọc theo nguyên tắc (utf-8) như sau để biết tiếng việt của bọn tao nào :
-
1: Với bit bắt đầu là “0” thì đọc 7 bit sau đó và dùng 7 bit này hình thành lên 1 code point tương ứng với 1 ký tự ( dạng sau: 0xxx xxxx. với x là các bit 1 hoặc 0 tùy ý hình thành nên code point )
-
2: Nếu bắt đầu là bit “1” và 2 bit liên tiếp theo đó là bit “10” thì sẽ ngầm hiểu sẽ dùng 2 byte liên tiếp để thể hiện giá trị code point cho ký tự theo dạng sau: 110xxxxx 10xxxxxx. với “10” là cú phát khai báo bắt buộc ở đầu byte thứ 2 để báo rằng nó là byte được dùng cùng với với byte đầu tiên . ( vậy ta có 11 số x để thể hiện codepoint )
-
Note: 1 byte gồm 8 bit xếp liên tiếp nhau , 2 byte gồm 16 bit liên tiếp nhau tương tự
-
3: Nếu bắt đầu là bit “11” và 2 bit liên tiếp theo đó là bit “10” thì sẽ ngầm hiểu sẽ dùng 3 byte liên tiếp để thể hiện giá trị cho ký tự theo dạng sau: 1110xxxx 10xxxxxx 10xxxxxx . với “10” là cú phát khai báo bắt buộc ở đầu byte thứ 2 và byte thứ 3 để báo rằng nó là byte được dùng cùng với với byte đầu tiên .
-
4: Nếu bắt đầu là bit “111” và 2 bit liên tiếp theo đó là bit “10” thì sẽ ngầm hiểu sẽ dùng 4 byte liên tiếp để thể hiện giá trị cho ký tự theo dạng sau: 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx . với “10” là cú phát khai báo bắt buộc ở đầu byte thứ 2 , byte thứ 3 và byte thứ 4 để báo rằng nó là byte được dùng cùng với với byte đầu tiên .
Không có tiếp theo nữa nhé vì utf8 chỉ hỗ trợ tối sử dụng 4 byte liên tiếp để thể hiện code point mà thôi.
Kết luận:
- Vậy nếu sử dụng UTF8 sẽ hỗ đọc linh hoạt từ 1 đến 4 byte liên tiếp để hình thành lên code point không có fix cứng số bit để thể hiện giá trị => sẽ tiết kiệm bộ nhớ.
- Máy tính sẽ dựa trên code-point và bảng mã utf8 cung cấp . máy tính sẽ biết được codepoint đó hiển thị như nào và mapping giữa codepoint và ký tự hình ảnh
- UTF8 là chuẩn đọc ký tự theo kiểu lấy 8 bit đầu xác định phạm vi có sử dụng các byte tiếp theo .
- UTF8 là bảng mã hỗ trợ máy tính liên kết từ các bit nhớ chuyển thành ký tự bao gồm cả tiếng việt .
Demo
Mình tạo 1 tập tin văn bản lưu trên hệ thống lưu theo định dạng utf8: Nội dung: hoàng kiên
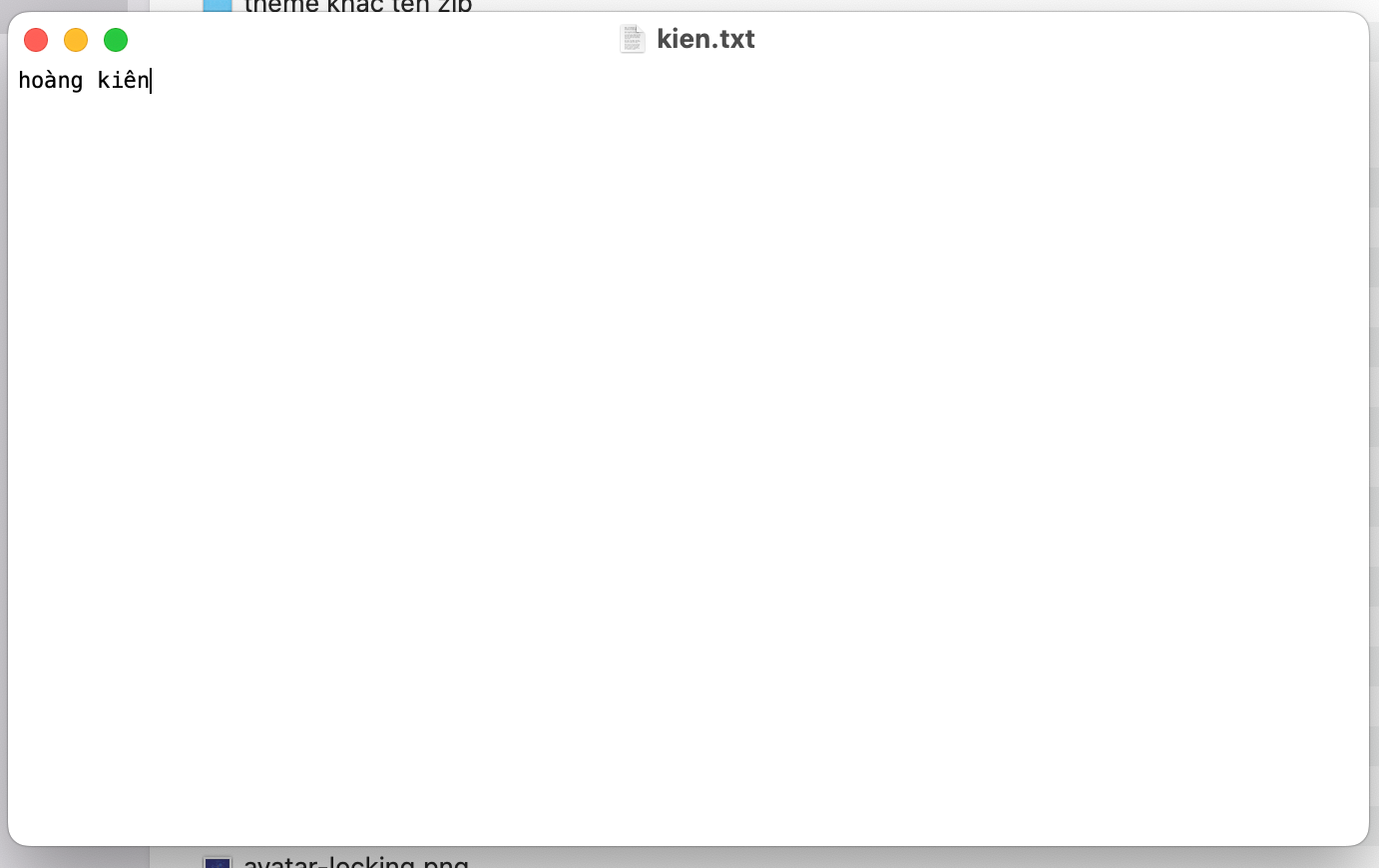
Cùng nhau xem bên trong các bit được lưu như thế nào để máy tính biết được nội dung đó là hoàng kiên nhé:
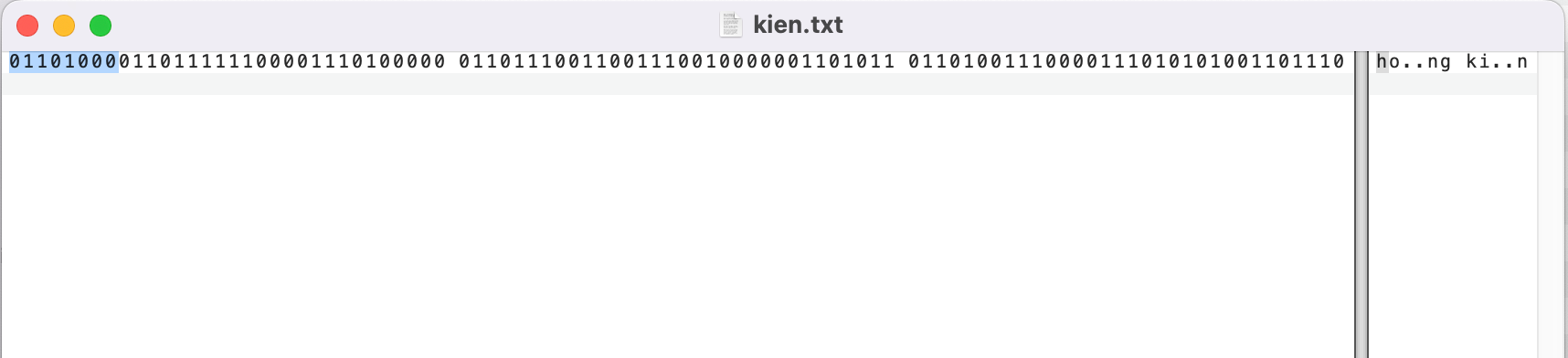
hoàng kiên tương ứng dãy bit mà các bạn nhìn thấy trong màn hình
Hệ xử lý sẽ đọc từ trái qua phải với 8 bit đầu tiên được bôi xanh sẽ tương ứng với từ “h” . bạn thấy không vì bit đầu tiên là bit 0 nên chỉ cần sử dụng 7 bit tiếp đó để hình thành code point tương ứng với “h”. (code point tương ứng : 1101000 với hệ 16 : 0068 -> liên kết với U+0068 trong utf-8)
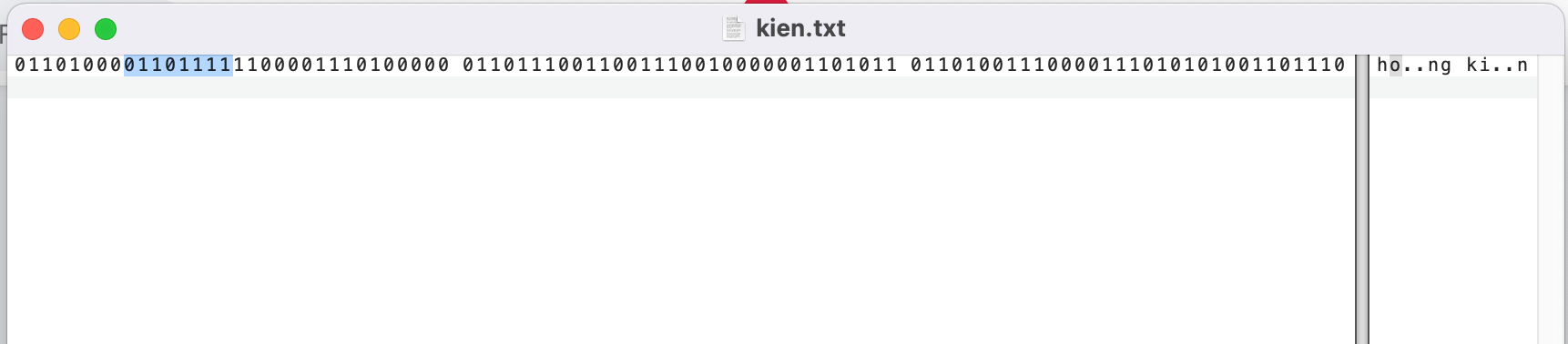
Hệ xử lý sẽ đọc từ trái qua phải với 8 bit tiếp theo được bôi xanh sẽ tương ứng với từ “o” . bạn tiếp tục thấy vì bit đầu tiên của 8 bit tiếp theo là bit 0 nên chỉ cần sử dụng 7 bit tiếp đó để hình thành code point tương ứng với “o”.( code point tương ứng : 1101111 với hệ 16 : 006F -> liên kết với U+006F trong utf-8)
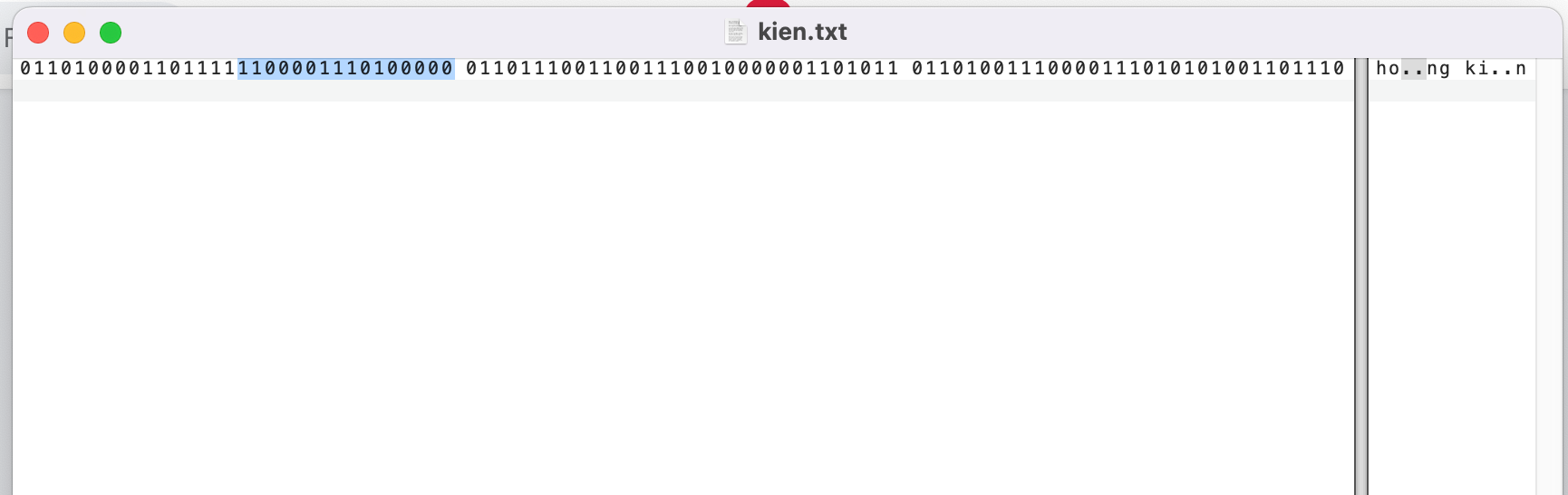
Và tiếp là từ “à” với bit đầu tiên là “110” trong 8 bit đầu thì ta sẽ lấy 2 byte liên tiếp để lấy ra code point (với mẫu là : 110xxxxx 10xxxxxx ) cụ thể ở trường hợp này ta lấy nguyên phần bôi xanh: 11000011 10100000 . so với mẫu thì ta sẽ có code point cụ thể là 00011 100000 ( Đổi sang hệ cơ số 16 là : E0 => tương ứng trong bảng mã utf8 là: U+00E0 ) và là ký tự “à”
Đó cách thức mà máy tính biết đến tiếng việt thông qua utf-8 được xử lý như vậy đó :D
https://www.charset.org/utf-8 bảng mã để ae tra thông tin về code-point và ký tự liên kết trong utf8
Hoàng Kiên 06/10/2022